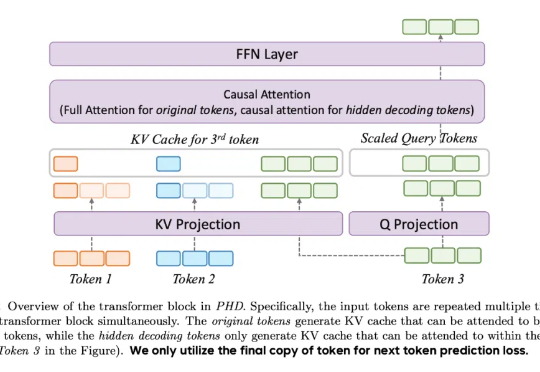
字节Seed团队PHD-Transformer突破预训练长度扩展!破解KV缓存膨胀难题
字节Seed团队PHD-Transformer突破预训练长度扩展!破解KV缓存膨胀难题最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
来自主题: AI技术研报
7752 点击 2025-04-28 14:09